二叉树算法 - 赫夫曼树及其构建
- 1 min数据结构与算法系列(三十九)
今天我们继续分享二叉树的一些应用:赫夫曼树。
我们日常使用压缩和解压软件的频率可谓是非常高,而最基本的压缩算法 —— 赫夫曼编码,其中使用的二叉树就是赫夫曼树。在介绍赫夫曼编码之前,我们先来介绍赫夫曼树。
###
什么是赫夫曼树
我们通过一个例子来引入什么是赫夫曼树。
我们在中小学每年期末考试结束后都会领到成绩单,成绩单上列出我们考试分数的等级,比如优秀(>=90)、良好(>=80)、合格(>=60)、不合格(<60),以某个班为例,总人数是100人,不同成绩区间的比例如下:

不考虑效率因素的话,我们可以这么实现成绩等级判定:
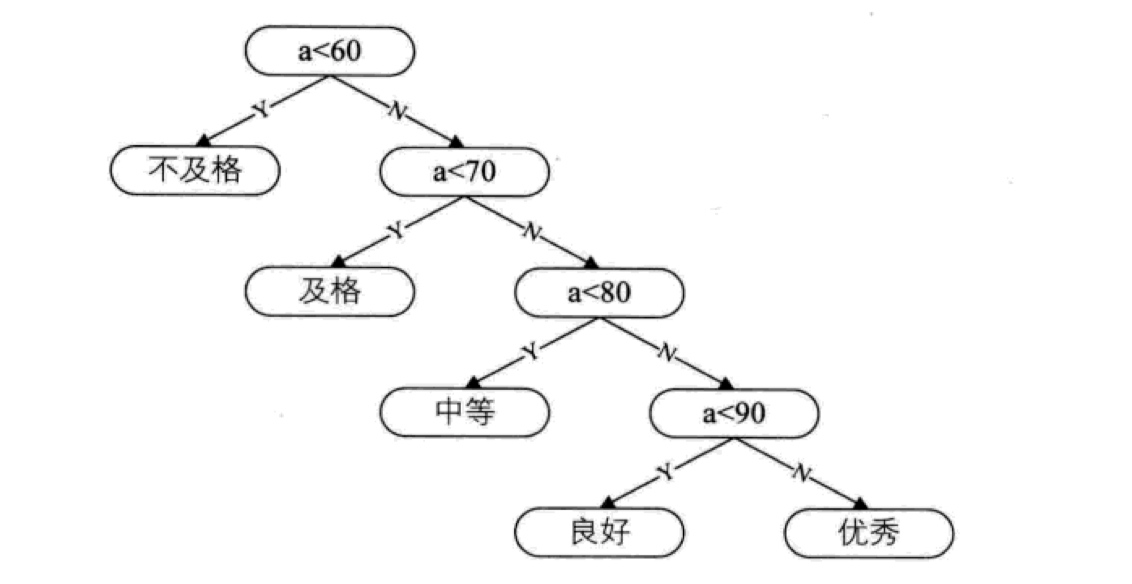
这种情况下,比例占80%以上的分数都需要经历三次以上的判断才能得到结果,显然不合理,对此,我们可以对判断逻辑进行改进:
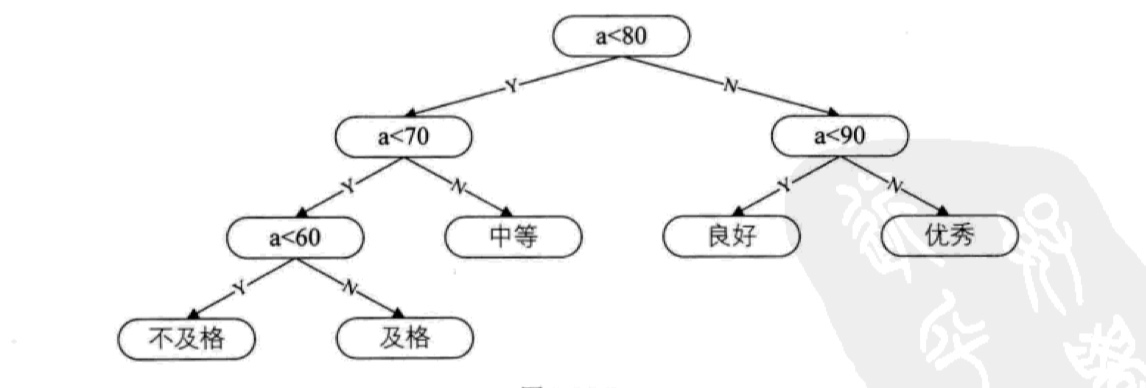
大部分同学的成绩都在80分左右,因此我们判断的逻辑改成了先通过80分对成绩进行划分,看起来效率是提升了,这其中的原理是每个分数都要循环调用此逻辑,将80分放到入口判断,总体判断次数更少,效率更高。
这就是赫夫曼树的雏形。显然,上述流程图可以抽象为一棵二叉树,每个等级的人数看作路径权重,我们把带权路径长度(权重*路径求和)最小的树叫做赫夫曼树,把上面两个流程图抽象为带路径权重的二叉树如下:
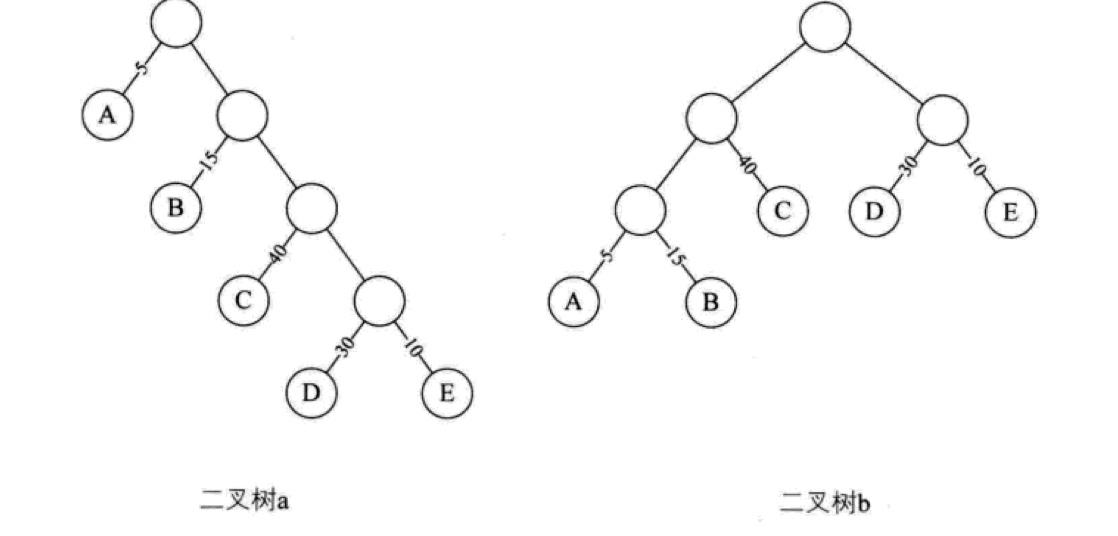
二叉树a的带权路径长度是 1*5+2*15+3*40+4*30+4*10 = 315,二叉树b的带权路径长度是 2*40+3*5+15*3+2*30+10*2 = 220,这意味着,对于人数100的班级,通过第一种方式要做315次比较,对于第二种方式,只需要220次比较,显然二叉树b比二叉树a更优。
###
赫夫曼树的构建
当然,上述二叉树b还不是赫夫曼树,因为它不是最优的,赫夫曼树的构造方式如下:
- 1、把有权值的节点按照从小到大顺序进行排序:A5、E10、B15、D30、C40;
- 2、取最小的两个节点作为某个新节点N1的子节点,较小的作为左子结点;
- 3、然后将N1替代A5和E10,插入上述有序序列,保持从小到大排序:N115、B15、D30、C40;
- 4、重复步骤2,将N1和B作为一个新节点N2的左右节点,依次类推,直到把所有节点纳入树中。
最终形成的二叉树如下所示:
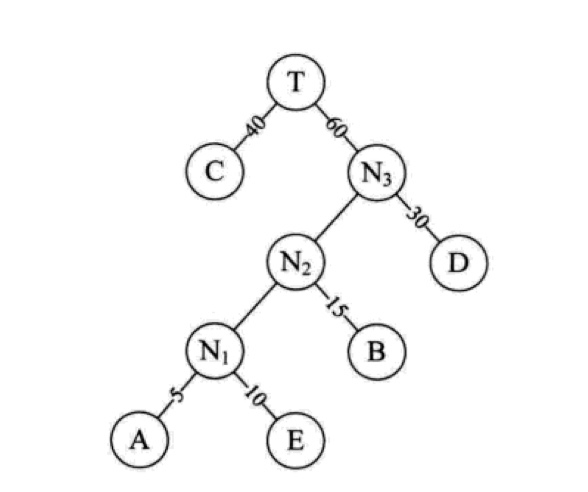
对应的带权路径长度是 1*40+2*30+3*15+4*5+4*10 = 205,对于100个学生而言,需要进行205次判断。比前面的二叉树b更优,同时也是最优的二叉树,所以是赫夫曼树。