字符串匹配算法 - Trie 树的定义、实现及应用
- 2 mins数据结构与算法系列(四十一)
介绍完树和二叉树的基本数据结构和算法之后,我们接着之前没讲完的字符串匹配算法。
Trie 树的定义
Trie 树,也叫「前缀树」或「字典树」,顾名思义,它是一个树形结构,专门用于处理字符串匹配,用来解决在一组字符串集合中快速查找某个字符串的问题。
注:Trie 这个术语来自于单词「retrieval」,你可以把它读作 tree,也可以读作 try。
Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起,比如我们有[hello,her,hi,how,seo,so]这个字符串集合,可以将其构建成下面这棵 Trie 树:
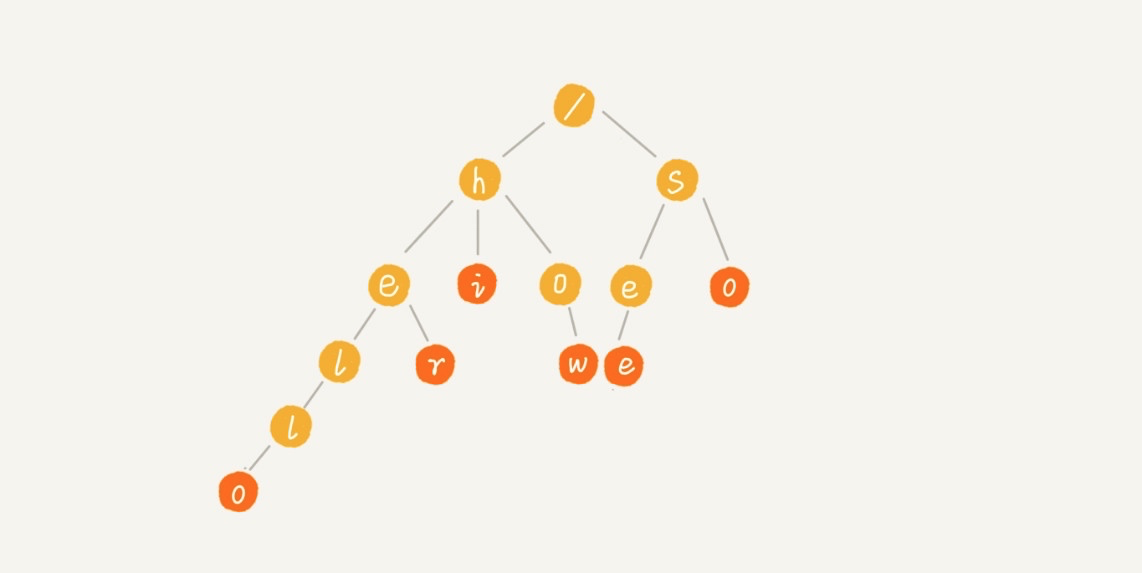
每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串(红色节点表示是某个单词的结束字符,但不一定都是叶子节点)。
这样,我们就可以通过遍历这棵树来检索是否存在待匹配的字符串了,比如我们要在这棵 Trie 树中查询 「her」,只需从 h 开始,依次往下匹配,在子节点中找到 e,然后继续匹配子节点,在 e 的子节点中找到r,则表示匹配成功,否则匹配失败。通常,我们可以通过 Trie 树来构建敏感词或关键词匹配系统。
如何实现 Trie 树
从刚刚 Trie 树的介绍来看,Trie 树主要有两个操作,一个是将字符串集合构造成 Trie 树。这个过程分解开来的话,就是一个将字符串插入到 Trie 树的过程。另一个是在 Trie 树中查询一个字符串。
Trie 树是个多叉树,二叉树中,一个节点的左右子节点是通过两个指针来存储的,对于多叉树来说,我们怎么存储一个节点的所有子节点的指针呢?
我们将 Trie 树的每个节点抽象为一个节点对象,对象包含的属性有节点字符、子节点引用和是否是字符串结束字符标志位:
class TrieNode
{
public $data; // 节点字符
public $children = []; // 存放子节点引用(因为有任意个子节点,所以靠数组来存储)
public $isEndingChar = false; // 是否是字符串结束字符
public function __construct($data)
{
$this->data = $data;
}
}
要构造一棵完整的 Trie 树,关键在于存储子节点引用的 $children 属性的实现。借助散列表的思想,我们通过一个下标与字符一一映射的数组,来构造 $children`:我们将字符串中每个字符转化为 ASCII 码作为数组下标,将对应节点对象引用作为数组值,依次插入所有字符串,从而构造出 Trie 树。对应 PHP 实现代码如下:
class Trie
{
private $root;
public function __construct()
{
$this->root = new TrieNode('/'); // 存储无意义字符
}
// 往 Trie 树中插入一个字符串
public function insert(array $text)
{
$p = $this->root;
for ($i = 0; $i < count($text); $i++) {
$index = ord($text[$i]) - ord('a');
if ($p->children[$index] == null) {
$newNode = new TrieNode($text[$i]);
$p->children[$index] = $newNode;
}
$p = $p->children[$index];
}
$p->isEndingChar = true;
}
// 在 Trie 树中查找一个字符串
public function find(array $pattern)
{
$p = $this->root;
for ($i = 0; $i < count($pattern); $i++) {
$index = ord($pattern[$i]) - ord('a');
if ($p->children[$index] == null) {
// 不存在 pattern
return false;
}
$p = $p->children[$index];
}
if ($p->isEndingChar == false) {
return false; // 不能完全匹配,只是前缀
}
return true; // 找到 pattern
}
}
但是这个 Trie 树只适用于 ASCII 编码字符,无法对更加复杂的字符集进行操作。对于 PHP 数组来说,我们完全可以将每个字符值作为下标,因为 PHP 数组本身就是散列表,这样就可以上述实现改造为直接支持中文的字符串匹配,改造后的代码如下:
class PhpTire
{
private $root;
public function __construct()
{
$this->root = new TrieNode('/'); // 存储无意义字符
}
// 往 Trie 树中插入一个字符串
public function insert($text)
{
$p = $this->root;
for ($i = 0; $i < mb_strlen($text); $i++) {
$index = $data = $text[$i];
if ($p->children[$index] == null) {
$newNode = new TrieNode($data);
$p->children[$index] = $newNode;
}
$p = $p->children[$index];
}
$p->isEndingChar = true;
}
// 在 Trie 树中查找一个字符串
public function find($pattern)
{
$p = $this->root;
for ($i = 0; $i < mb_strlen($pattern); $i++) {
$index = $pattern[$i];
if ($p->children[$index] == null) {
// 不存在 pattern
return false;
}
$p = $p->children[$index];
}
if ($p->isEndingChar == false) {
return false; // 不能完全匹配,只是前缀
}
return true; // 找到 pattern
}
}
我们可以编写一段简单的测试代码:
$trie = new PhpTire();
$strs = ['Laravel', '', 'Framework', '学院', 'PHP'];
foreach ($strs as $str) {
$trie->insert($str);
}
if ($trie->find('小号')) {
print '包含这个字符串';
} else {
print '不包含这个字符串';
}
结果会返回「不包含这个字符串」。
Trie 树的复杂度
构建 Trie 树的过程比较耗时,对于有 n 个字符的字符串集合而言,需要遍历所有字符,对应的时间复杂度是 O(n),但是一旦构建之后,查询效率很高,如果匹配串的长度是 k,那只需要匹配 k 次即可,与原来的主串没有关系,所以对应的时间复杂度是 O(k),基本上是个常量级的数字。
Trie 树显然也是一种空间换时间的做法,构建 Trie 树的过程需要额外的存储空间存储 Trie 树,而且这个额外的空间是原来的数倍。
你会发现,通过 Trie 树进行字符串匹配和之前介绍的 BF 算法和 KMP 算法有所不同,BF 算法和 KMP 算法都是在给定主串中匹配单个模式串,而 Trie 树是将多个模式串与单个主串进行匹配,因此,我们将 BF 和 KMP 这种匹配算法叫做单模式匹配算法,而将 Trie 树这种匹配算法叫做多模式匹配算法。
Trie 树的应用
Trie 树适用于那些查找前缀匹配的字符串,比如敏感词过滤和搜索框联想功能。
1、敏感词过滤系统
2016 年新广告法推出后,为之前的公司商品库做过一个简单的敏感词过滤系统,就用到了 Trie 树来对敏感词进行搜索匹配:首先运营在后台手动更新敏感词,底层通过 Tire 树构建敏感词库,然后当商家发布商品时,以商品标题+详情作为主串,将敏感词库作为模式串,进行匹配,如果模式串和主串有匹配字符,则以此为起点,继续往后匹配,直到匹配出完整字符串,然后标记为匹配出该敏感词(如果想嗅探所有敏感词,继续往后匹配),否则将主串匹配起点位置往后移,从下一个字符开始,继续与模式串匹配。
2、搜索框联想功能
另外,搜索框的查询关键词联想功能也是基于 Trie 树实现的:
进而可以扩展到浏览器网址输入自动补全、IDE代码编辑器自动补全、输入法自动补全功能等。