查找算法 - 二分查找
- 1 min数据结构与算法系列(十四)
介绍完基本的排序算法后,今天我们来介绍一种常见的高效查找算法 —— 二分查找。在介绍二分查找之前,对于基于数字索引的数组元素的查找,我们可能第一反应都是遍历这个数组,直到给定数组元素值和待查找的值相等时,返回索引值并退出,否则一直遍历到最后一个元素,如果还是没有找到则返回-1,这样的查找虽然是简单粗暴了点,但是对于规模不大的数据集,也是没什么问题的,但是很明显,对于n个元素的数组,这种查找的时间复杂度是 O(n),随着数据规模的增加,性能会越来越差,设想如果数据集的长度是 40 亿(约2的32次方),那么最差的情况需要遍历数组 40 亿次,简直不敢想象需要花费多长时间!那有没有性能搞好的算法来解决这个问题呢?
在进一步探讨这个问题之前,我们先来看一个生活中的例子。我们日常生活中,很多人应该有这种经历,朋友、同学或者同事淘了个宝贝,神秘兮兮的过来让大家猜多少钱,在约定一个价格范围之后(比如10-100),大家会七嘴八舌的猜起价格来:
「50」
「高了」
「30」
「低了」
「40」
「高了」
「36」
「对了」
如果我们用顺序遍历的逻辑,最差需要91次,才能猜到价格,现实生活中,没人会这么干,我们采用上面这种逻辑,只需要4次就猜到价格了,快了几十倍,而且数据量越大,优势越明显。基于这种思路,我们的算法科学家提炼出了二分查找算法帮助我们在给定数据集中快速定位要查找的元素。
所谓二分查找,针对的是一个有序的数据集合(这点很重要),查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。注意到二分查找针对的必须是已经排序过的有序数组,否则不能使用该算法。图示如下: 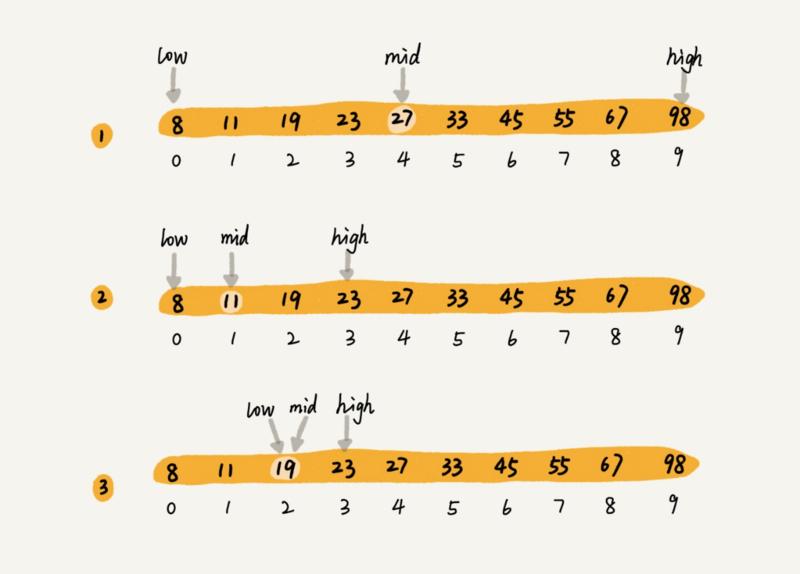
思路比较简单,我们将其通过 PHP 代码实现如下:
<?php
function binary_search($nums, $num)
{
return binary_search_internal($nums, $num, 0, count($nums) - 1);
}
function binary_search_internal($nums, $num, $low, $high)
{
if ($low > $high) {
return -1;
}
$mid = floor(($low + $high) / 2);
if ($num > $nums[$mid]) {
return binary_search_internal($nums, $num, $mid + 1, $high);
} elseif ($num < $nums[$mid]) {
return binary_search_internal($nums, $num, $low, $mid - 1);
} else {
return $mid;
}
}
$nums = [1, 2, 3, 4, 5, 6];
$index = binary_search($nums, 5);
print $index;
很显然,二分查找的时间复杂度是 O(logn)。这是一个非常恐怖的数量级,有时候甚至比 O(1) 还要高效,比如我们要在开头提到的 40 亿个数字中查找某一个元素,也只需要32次(2的32次方是40亿数量级),这真的是非常高效了,正因如此二分查找在线性表结构中的应用非常广泛。但是使用二分查找需要注意一个前提,那就是针对有序数组,换言之,二分查找适用于变动不是很频繁的静态序列集,如果序列集变动很频繁,经常进行插入删除操作,那么就要不断维护这个序列集的排序,这个成本也很高,因此,这种情况下就不适用二分查找了,比如我们的数据库查询,增删改查很频繁,显然不是通过二分查找来进行查询的,后面我们会讨论,如何针对动态变化的序列集进行查询操作。