计算机网络协议系列 - HTTP 协议篇:HTTP 缓存工作机制和实现原理(上)
- 1 min计算机网络协议系列(四十五)
首先需要声明的是,我们这里讨论的缓存是基于 HTTP 协议实现的缓存,这些缓存通常存储在 HTTP 客户端,通过请求头或响应头来协商和标识,而不是那些存储在 Memcached 或者 Redis 服务器中的缓存,后者更多用来缓存从数据库中获取的数据。
为什么需要缓存
在通过客户端访问服务器时,对于某些静态资源文件或页面(比如 HTML 文档、CSS、JavaScript 文件、图片等),它们变动的频率很小,同一个客户端发起多次请求返回的都是同一个文件,这样就会对服务器的带宽造成浪费,同时也会加重 Web 服务器的负载,降低 Web 服务器的性能。如果在客户端首次获取到这些静态文件后,将这些变动频率很低的静态文件缓存到客户端,这样,客户端下次发起请求时,就可以直接从本地获取对应的缓存文件,不必每次都从服务器获取,就可以提高服务器的负载,进而提升服务器的性能,同时还会减少网络流量,降低客户端请求等待延迟,从而提升客户端用户的体验,这就是 HTTP 缓存的意义。
HTTP缓存的种类
HTTP 缓存的种类有很多,但大致可以分为私有缓存和共享缓存两种:
- 私有缓存:作用于单个用户,通常就是浏览器缓存;
- 共享缓存:往往存放在可以被多个用户共享的代理之中,所以有时候也叫代理缓存。
除此之外还有网关缓存也属于 HTTP 缓存,反向代理缓存、CDN 缓存都属于其范畴之内,这些更加复杂的缓存我们放到后续去讨论,而代理缓存往往存储在公司或 ISP 服务商假设的作为本地网络一部分的 Web 代理中,也不是我们本篇重点讨论的内容,所以接下来我们主要以客户端浏览器缓存为例来介绍 HTTP 缓存的工作机制和实现原理。
HTTP缓存的工作机制
虽然 HTTP 缓存的种类繁多,构建机制也不尽相同,但基本工作原理是一致的,无外乎以下这几个步骤:
- 接收:读取请求报文;
- 解析:对请求报文进行解析,提取 URL 和各种首部字段;
- 查询:查看是否有本地缓存可用,如果没有,则从服务器获取相应的资源并存储到本地;
- 新鲜度检查:缓存不会一直有效,所谓的「新鲜度」指的是和食品的保质期类似,缓存是有有效期的,在有效期之内才可以使用,否则需要向服务器查询对应资源是否有更新;
- 创建响应:缓存会用新的首部和缓存的响应主体来构建响应报文;
- 发送:将响应发送给客户端;
- 日志:缓存可以创建一条日志来记录这个 HTTP 事务。
所以,总结下来,一个 HTTP 请求的缓存处理流程如下:
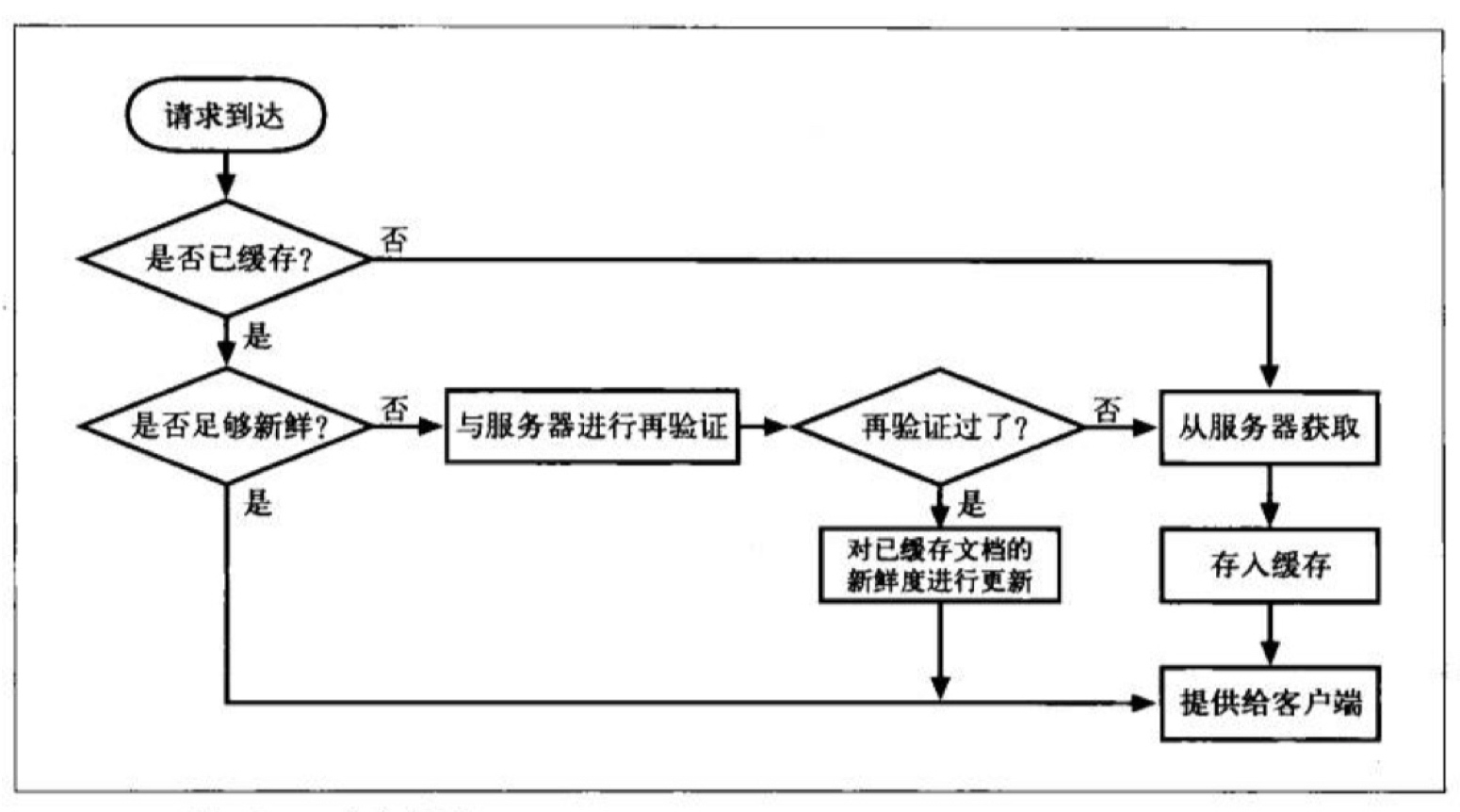
另外,需要注意的是通常我们只会对 GET 请求资源进行缓存,因为只有 GET 请求不会对资源实体的状态进行改变,OPTIONS 请求不返回响应实体没有缓存的意义,而其他诸如 POST、PUT、DELETE、PATCH 这些会改变资源状态的请求则不能进行缓存。
HTTP缓存的实现原理
基于 HTTP 协议的 HTTP 缓存是通过在请求头和响应头中设置相应的字段值来实现的,下面我们将详细介绍比较常见的缓存相关首部字段,比如 Expires、Cache-Control、Last-Modified/If-Modified-Since、Etag/If-None-Match 等。
1)Expires
Expires 字段的值为服务端返回的缓存资源到期时间(绝对时间),即下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。
不过 Expires 是 HTTP/1.0 的东西,现在浏览器均默认使用 HTTP/1.1,所以它的作用基本忽略。
另一个问题是,到期时间是由服务端生成的,但是客户端时间可能跟服务端时间有误差,这就会导致缓存命中的误差。所以 HTTP/1.1 使用 Cache-Control 替代该字段。而且如果在 Cache-Control 响应头设置了 max-age 或者 s-max-age 指令,那么 Expires 头也会被忽略。
下一篇我们将继续探讨基于 Cache-Control、Last-Modified/If-Modified-Since、Etag/If-None-Match 这三种方式实现 HTTP 缓存。